projects
A growing collection of 🆒 projects
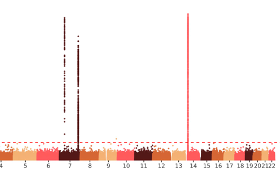
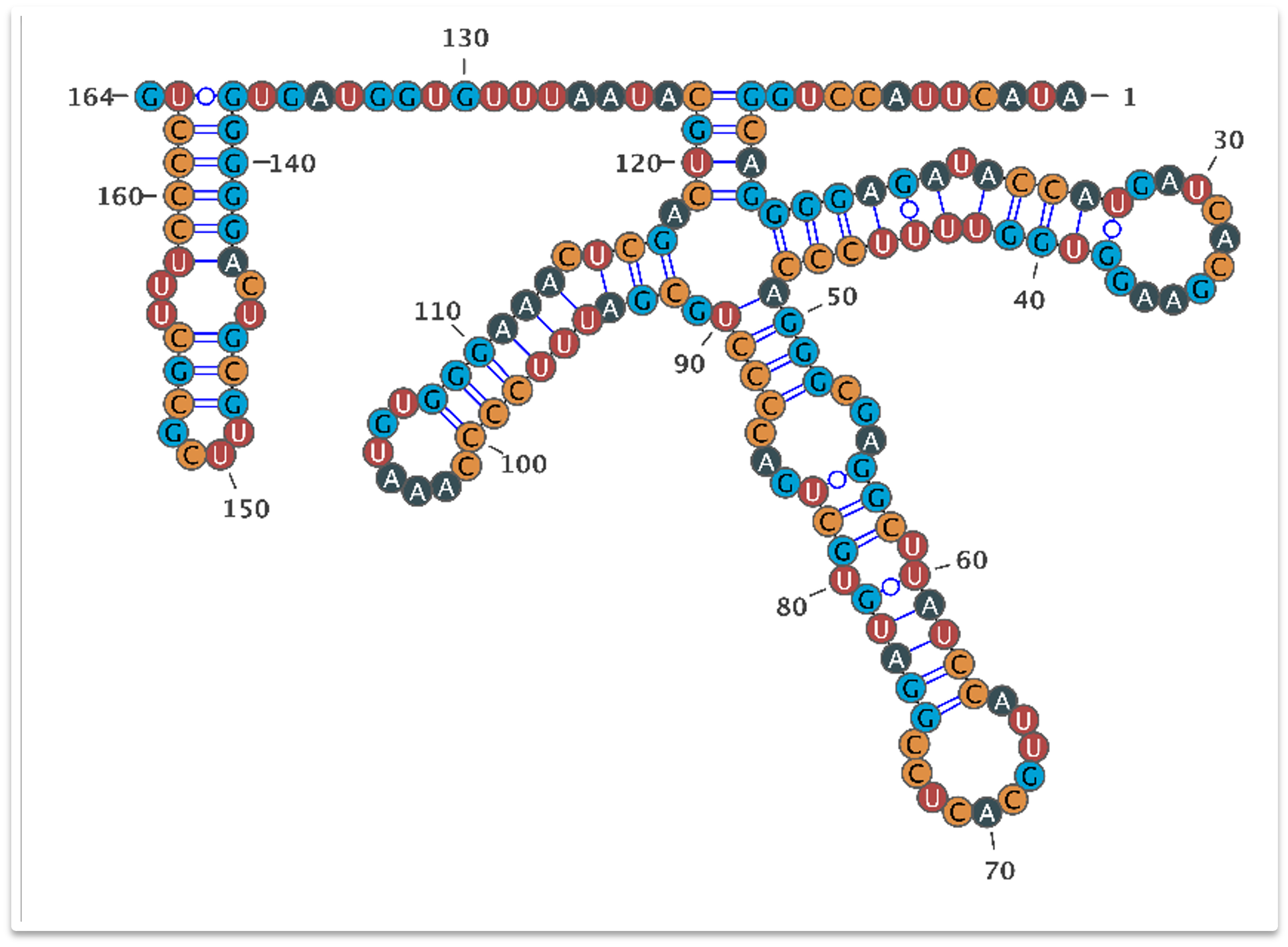
Life consists of countless biological molecules such as DNA and RNA sequences. Comprehensively and collectively assessment of these biomolecules is termed as “omics”. For instance, genomics and transcriptomics refer to studying the entire set of DNA and RNA sequences within biological samples, respectively. Omics technologies have revolutionized biomedical research by providing unbiased assays for these biomolecules. Over the past two decades, we have witnessed numerous advances in omics technologies: from the first draft of human genome assembly in 2001 to half a million whole genomes being sequenced by a single biobank, from the first transcriptomic sequencing of bulk samples in mid 2000s to the currently widespread usage of single cell and spatial transcriptomic profiling, and from short-read next generation sequencing to nowadays long-read sequencing capable of capturing every single base pair from telomere to telomere.
The advent of new omics technologies has enabled us to answer fundamental biological questions and deciphering molecular mechanisms underlying complex human diseases from many new angles. However, these data-intensive technologies have also posed unprecedented “big data” challenges. Almost all new omics experiments generate tons of high dimensional data and one project usually involves multiple types of such high-throughput readouts. Thus, state-of-the-art data science techniques are indispensable for us to derive biological insights from these data. The broad goal of our research is to gain mechanistic insights about human diseases by applying modern computational methods to modern multi-omics data.
Here you can read more about the three main research topics we have at the moment: